Experience
Jane Street New York City, NY
Software Engineer Intern
Roblox San Mateo, CA
Software Engineer Intern
Software Engineer Intern
May 2025 - Present
Roblox San Mateo, CA
Software Engineer Intern
May 2024 - August 2024
Created the engine’s first service for automated pre-release performance regression detection and bisection
Rolled out a suite of C++ tools for profiling and visualizing memory usage across all platforms and profiler backends
Implemented ML enhancements for memory analyzers and directly integrated into TeamCity, Jira, and Slack CI/CD
Applied projects to instantly catch and report multiple regressions, improving overall allocations per second by 8.3%
May 2023 - August 2023
Released Roblox’s real-time aerodynamics model to 66 million DAU as part of fluids engine team
Designed and developed a working prototype of a full multiphase real-time fluid dynamics model
Redesigned, stabilized, and extended buoyancy force interactions for low-density and air-buoyant objects
Optimized memory overhead of aerodynamics implementation by 64%, on average
Research
Brown Particle Astrophysics Lab Providence, RI
Undergraduate Researcher
NASA Langley Research Center Hampton, VA
Machine Learning Research Intern
Undergraduate Researcher
January 2024 - Present
Recipient of 2024 Spring UTRA grant for “Machine Learning for Dark Matter Search in LUX-ZEPLIN (LZ) Experiment”
Designing generative autoencoders and physics-based networks to reduce the petabyte-scale raw dataset size of LZ by over 1000x
Led one of six modules at the 2025 CFPU AI Winter School. Introduced the latest research in autoencoders for dark matter detection experiments and led a workshop. The event registered over 2,000 undergraduate, masters, and doctoral participants globally.
NASA Langley Research Center Hampton, VA
Machine Learning Research Intern
September 2021 - May 2022
Developed a proprietary multimodal deep learning-based flow solver for 2D flows
Investigated viability of FUN3D flow solver for simulating dense rotary aircraft using the MUST experiment
Designed simulation environments and ran experiments on clusters with Slurm, Tecplot
Projects
Jump to:
| ATA | Artificial Teaching Assistant |
| ANT | Artificial Neural Topology |
| Sandblox4D | 4D Voxel-based Sandbox Game |
| LIGAND | Locus Inference and Generative Adversarial Network for gRNA Design |
| worldNET | Sparse Continuous Interpolation for Image Geopositioning |
| NeuroVision | Multimodal Deep Learning Prediction of Higher-Order Cognition |
| BAST | Boid-Agent Simulation of Transmition in Routine Closed Systems |
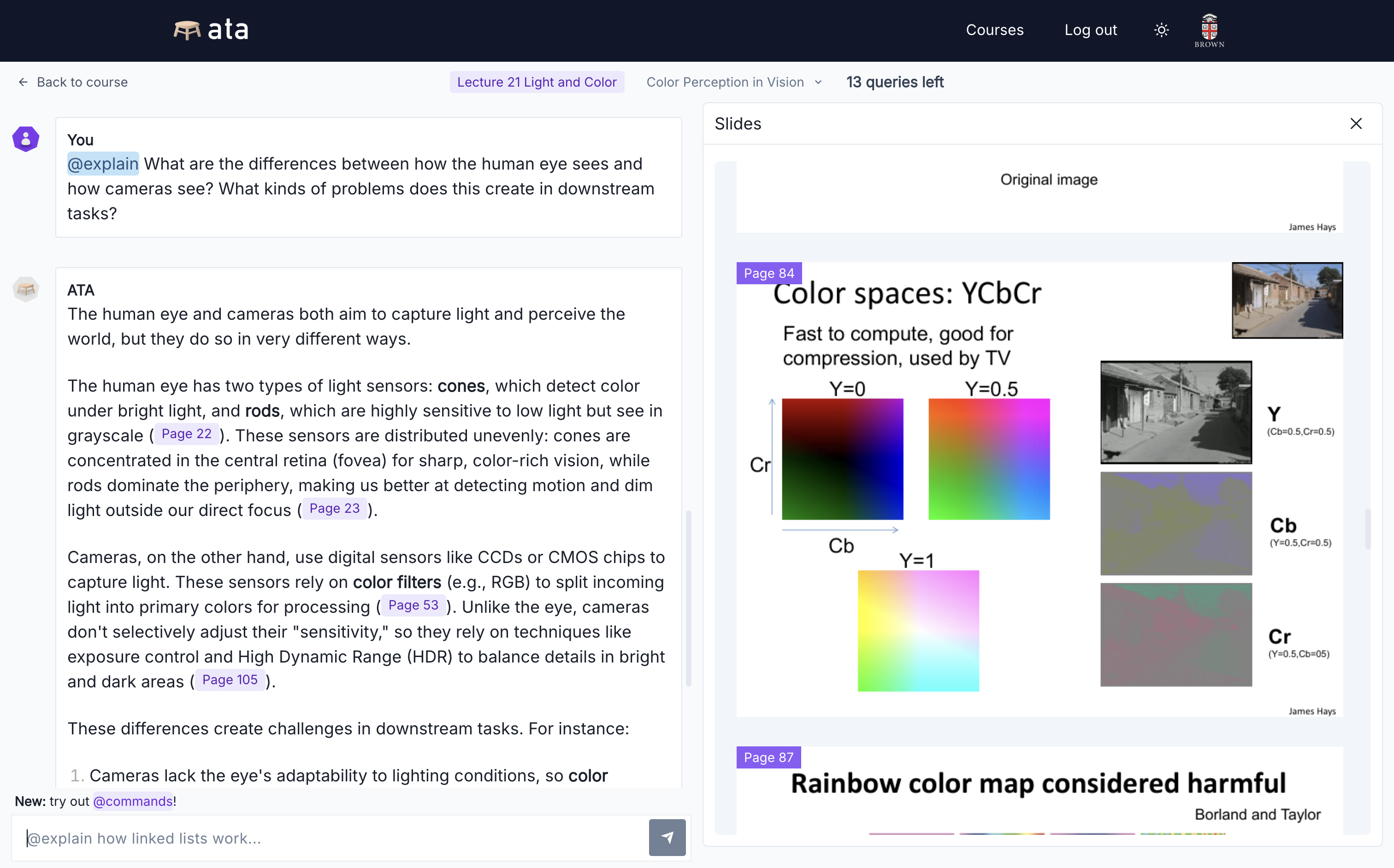
Artificial Teaching Assistant (ATA)
ATA is a socratic, course-immersed AI teaching assistant.
Overview
ATA is a project started by myself and two other students at Brown in Spring 2024 with the goal of building AI tools for students and teaching staff to improve rather than hinder learning outcomes.
Currently, it consists of a student-facing AI chatbot that acts as a tutor. Professors can drop in their course materials and distribute the course link to students, who can then chat with ATA about lectures and assignments. Professors recieve course-specific analytics on student pain points, and students recieve equitable benefit from the latest LLMs paired with their course content--models otherwise paywalled by their corporate proprietors.
ATA is still experimental, and we hope to spark productive conversation around the future of AI in education as we learn what kind of tools should be created.
ATA is university-sanctioned and in use by hundreds of students across multiple courses at Brown.
Collaborators
Julian Dai, Noah Rousell
Artificial Neural Topology (ANT)
Overview
Rapid development in artificial intelligence (AI) research has led to increasingly larger artificial neural networks (ANNs). Some of the largest ANNs now have parameter sizes that rival the neuron and synaptic counts of intelligent biological organisms. However, these models have yet to demonstrate the capacity to reason in areas outside of their training domain, leaving a gap in AI research efforts towards artificial general intelligence (AGI).
The combined inability of ANNs to replicate the complex graph structure and temporal statefulness of information travel in biological neural circuits we believe results in ANN hypothesis classes that are too narrow for general reasoning. To address both of these issues, we propose ANT, a stateful, toplogoically nonlinear network formulation.
 |
 |
Unlike other RL formulations, ANT trains with a combined gradient descent and genetic algorithm to properly search the enlarged hyperparameter space brought upon by lifted restrictions on the neural graph.
Results and Current Direction
We found that ANT demonstrates superior performance and task-generalizable capabilities in reinforcement learning (RL) settings compared to conventional artificial neural networks. Specifically, we were able to demonstrate that, with equal parameters, ANT converged quicker, more regularly, and to a better solution than an analogous ANN running on a similar algorithm.
ANT has unique computational benefits and challenges associated with it. Unlike neural networks which have linear complexity with respect to depth and sublinear complexity elsewhere, ANT has linear complexity with respect to neuron size but is entirely parallelizable, as individual neuron computations can be performed independently.
Collaborators
Jonah Schwam (M.S. CS, Brown University), Pavani Nerella (M.S. CS, Brown University), Ilija Nikolov (Ph.D. Physics, Brown University), Taishi Nishizawa (M.S. CS, Brown University)
Sandblox 4D
Sandblox is a Minecraft-like creative sandbox game reimagined in four spatial dimensions built from the ground-up with C++ and OpenGL.
Overview
Sandblox is a voxel-based sandbox game like many others: you can place and break blocks, explore terrain and caves, find ore, and even fly around. But, Sandblox has one major twist. The three dimensional world in Sandblox is just a user-controllable cross-section of 4-dimensional terrain, generated with 4D simplex noise. Watch the video demonstration to learn more about how this works, and skip to 1:33 to see it in action.
Collaborators
Siddarth Sitaraman
LIGAND
LIGAND is a model capable of generating effective and minimally offsite-active gRNA for arbitrary DNA loci.
Overview
The advent of Clustered Regularly Interspaced Short Palindromic Repeats (CRISPR) technology, notably the CRISPR-Cas9 system—an RNA-guided DNA endonuclease-introduces an exciting era of precise gene editing. Now, a central problem becomes the design of guide RNA (gRNA), the sequence of RNA responsible for locating a bind location in the genome for the CRISPR-Cas9 protein. While existing tools can predict gRNA activity, only experimental or algorithmic methods are used to generate gRNA specific to DNA subsequences. In this study, we propose LIGAND, a model which leverages a generative adversarial network (GAN) and novel attention-based architectures to simultaneously address on- and off- target gRNA activity prediction and gRNA sequence generation. LIGAND’s generator produces a plurality of viable, highly precise, and effective gRNA sequences with a novel objective function consideration for off-site activity minimization, while the discriminator maintains state-of-the-art performance in gRNA activity prediction with any DNA and epigenomic prior. This dual functionality positions LIGAND as a versatile tool with applications spanning medicine and research.
Collaborators
Pratham Rathi (M.S. CS, Brown University), Taj Gillin, Zhen Ren (M.S. CS, Brown University)
worldNET
worldNET is an Image-to-GPS (Im2GPS) model capable of determining locations of images from places it has not seen in training. It does this through a learned nonlinear interpolation over locations it has seen, thus imputing a feature map of the world.
Overview
worldNET is a continuous approach to solving the image-to-GPS problem in computer vision. Our model incorporates an "interpolation head" that is trained to produce a set of geographic interpolation weights from outputs of a fine-tuned version of VGG. By composing weights of known locations, worldNET is able to predict the locations of images in regions it has never seen before with a better idea of the spatial relationship between features.
Collaborators
Nuo-Wen Lei, Mindy Kim
NeuroVision
NeuroVision is a model which uses multiple modes of brain biometric data to attempt to predict behavioral characteristics.
Overview
In recent years, there has been significant research into applications of deep neural networks to brain biometric data. Most work has been done on the classification of neurological disorder by evaluating abnormalities in either MRI or EEG data, but there has been little focus, in the conventional sense or with novel deep learning methods, on the prediction of higher-order behavioral cognition. My goal is to predict over an array of behavioral metrics (CVLT, LPS, RWT, TAP, TMT, WST) using a supervised 3D Deep Convolutional Neural Network (DCNN) paired with an EEGNet-based 2D DCNN to interpret both MRI and EEG data. We hypothesize that a deep learning model will be able to detect and interpret structures and activities in the brain that indicate certain behavioral characteristics.
Collaborators
Vandana Ramesh (M.S. CS, Brown University), Micah Lessnick (M.S. CS, Brown University)
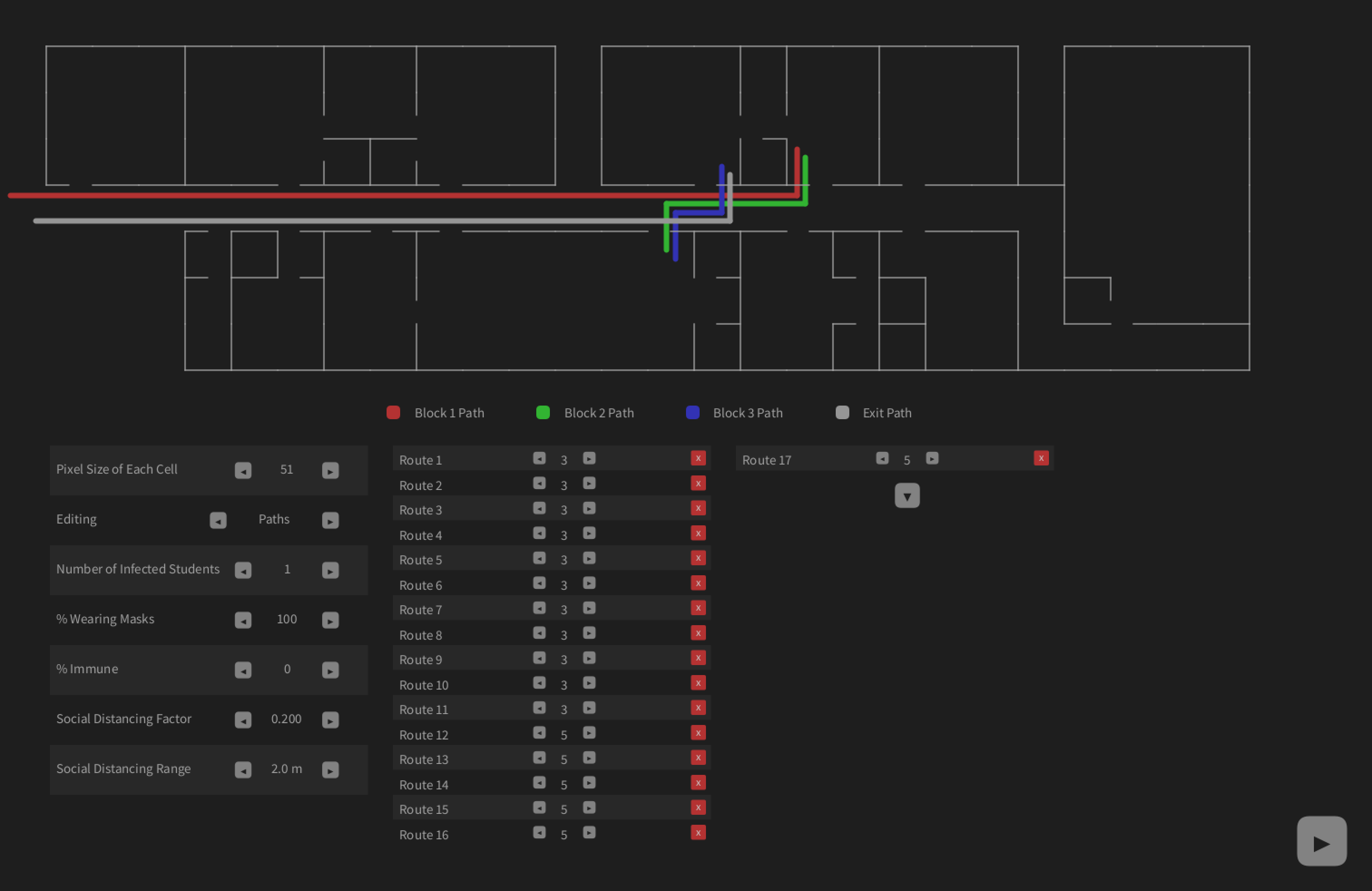
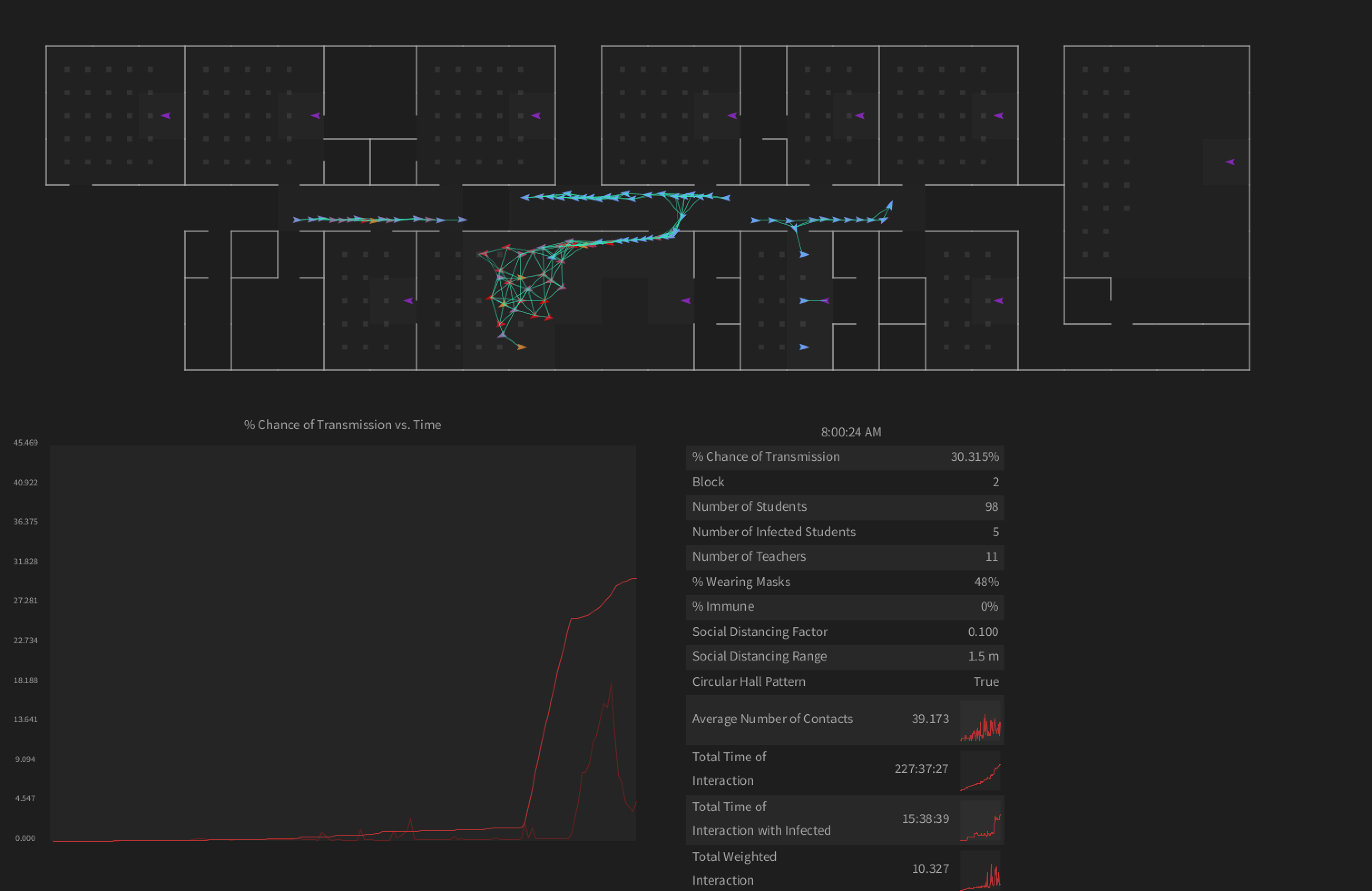
Boid-Agent Simulation of Transmission in Routine Closed Systems
Epidemiological simulation software implemented in NHREC schools during the 2020-2021 school year for assessing COVID-preventative measures.
GitHub